|
Radostin Cholakov I'm a CS student at Stanford University focused on efficient large language models (quantization), novel architectures (discrete diffusion), reasoning, and representation learning. From Barutin, Bulgaria. Since 2014 some call me Radi Cho :D |
Papers |

|
Per-Axis Weight Deltas for Frequent Model Updates Stefan Kuyumdzhiev, Radostin Cholakov NeurIPS 2025 Workshop on Continual and Compatible Foundation Model Updates, 2025. Oral paper · code We compress fine-tuned LLM checkpoints into 1-bit weight deltas to reduce storage and latency overhead for multi-variant serving. Our approach dynamically selects between per-row or per-column scaling for each layer to better capture axis-specific patterns in weight residuals. This leads to improved reconstruction quality over scalar alternatives on benchmarks while keeping model artifacts 5.24× smaller than full FP16 checkpoints. |
|
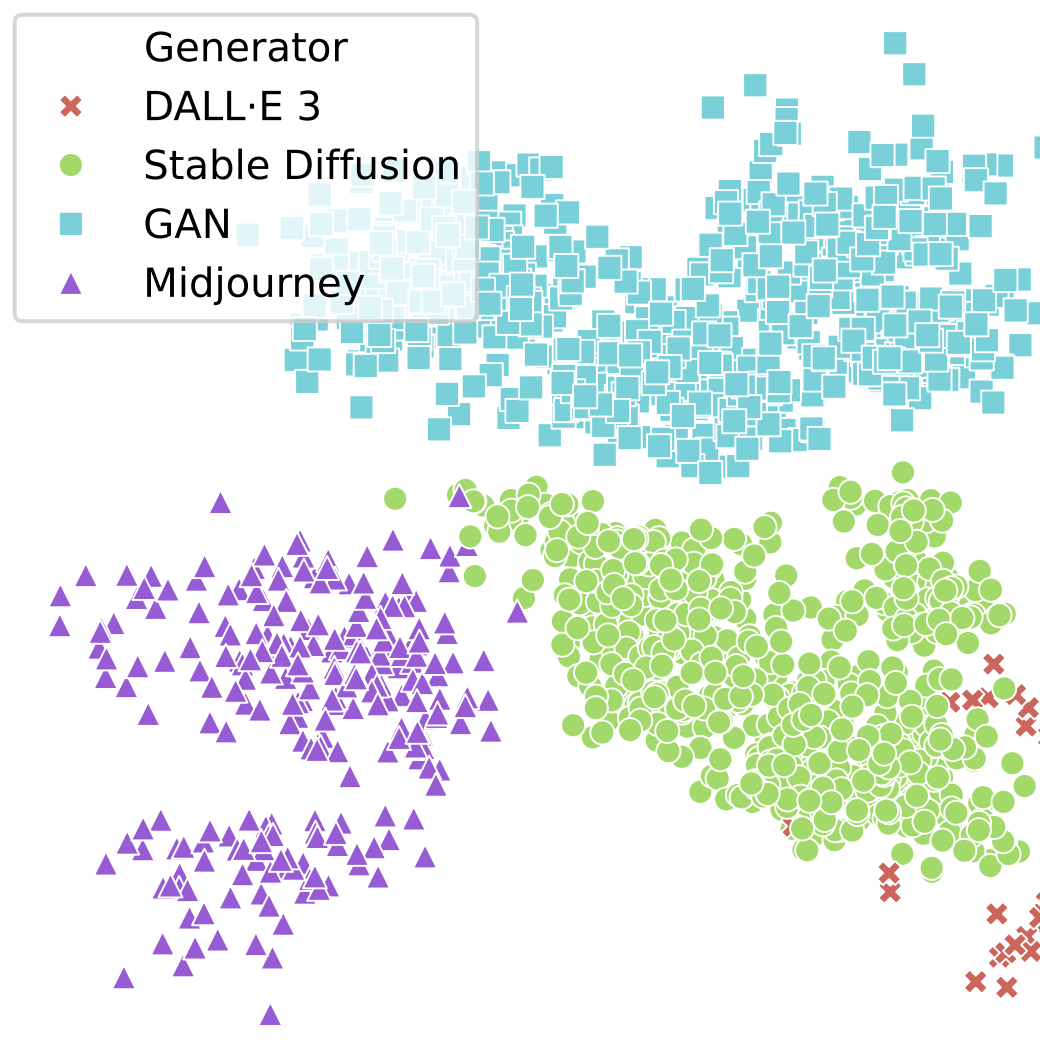
ImagiNet: A Multi-Content Benchmark for Synthetic Image
Detection Delyan Boychev, Radostin Cholakov AAAI 2025 Workshop on Datasets and Evaluators of AI Safety, 2025. Oral paper · dataset ImagiNet provides 200K high-resolution examples across photos, paintings, faces, and miscellaneous to improve generalization of synthetic image detectors. A SelfCon-trained ResNet‑50 sets strong baselines, reaching up to 0.99 AUC and 86–95% balanced accuracy with robustness to compression and resizing. |
|
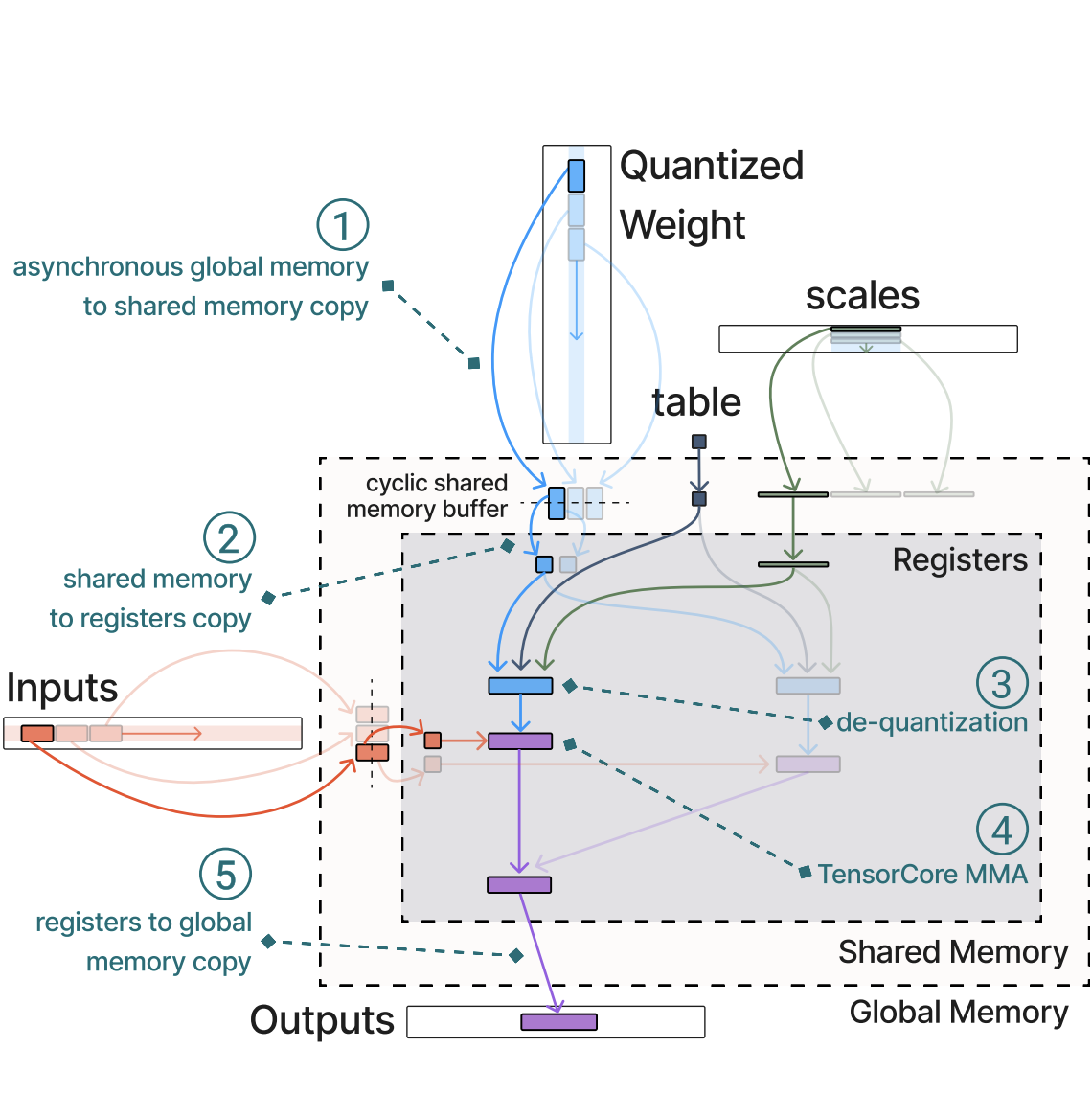
Fast Matrix Multiplications for Lookup Table-Quantized
LLMs Han Guo, William Brandon, Radostin Cholakov, Jonathan Ragan-Kelley, Eric P. Xing, Yoon Kim Findings of EMNLP, 2024. paper · code · models We introduce FLUTE, a flexible LUT engine that fuses dequantization and matmul for non-uniform low-bit weights, reducing unpacking overhead and shared-memory contention. At batch sizes < 32 and group size 128, FLUTE is 2–4× faster than strong GEMM baselines, yielding 1.5–2× end-to-end throughput gains while maintaining competitive accuracy. |
|
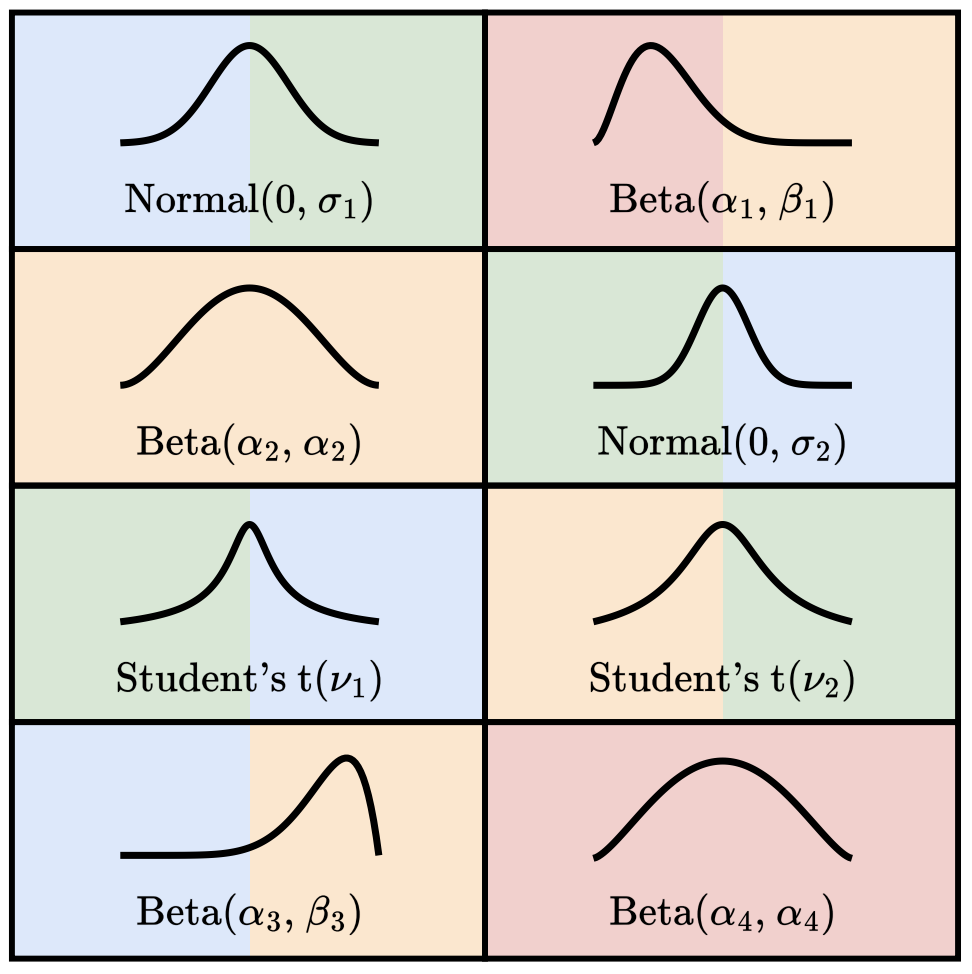
Distributional Quantization of Large Language
Models Radostin Cholakov, Han Guo, Yoon Kim CEE RSI Distinguished Papers, 2023. paper We quantize LLM weights to 4 bits using block-wise quantiles from fitted distributions (Gaussian, Beta, Student’s t) and a numerical optimizer to minimize reconstruction loss. The approach reduces error over prior 4-bit quantile methods at equal storage and achieves state-of-the-art perplexity on LLaMA‑2 for WikiText‑2. |
|
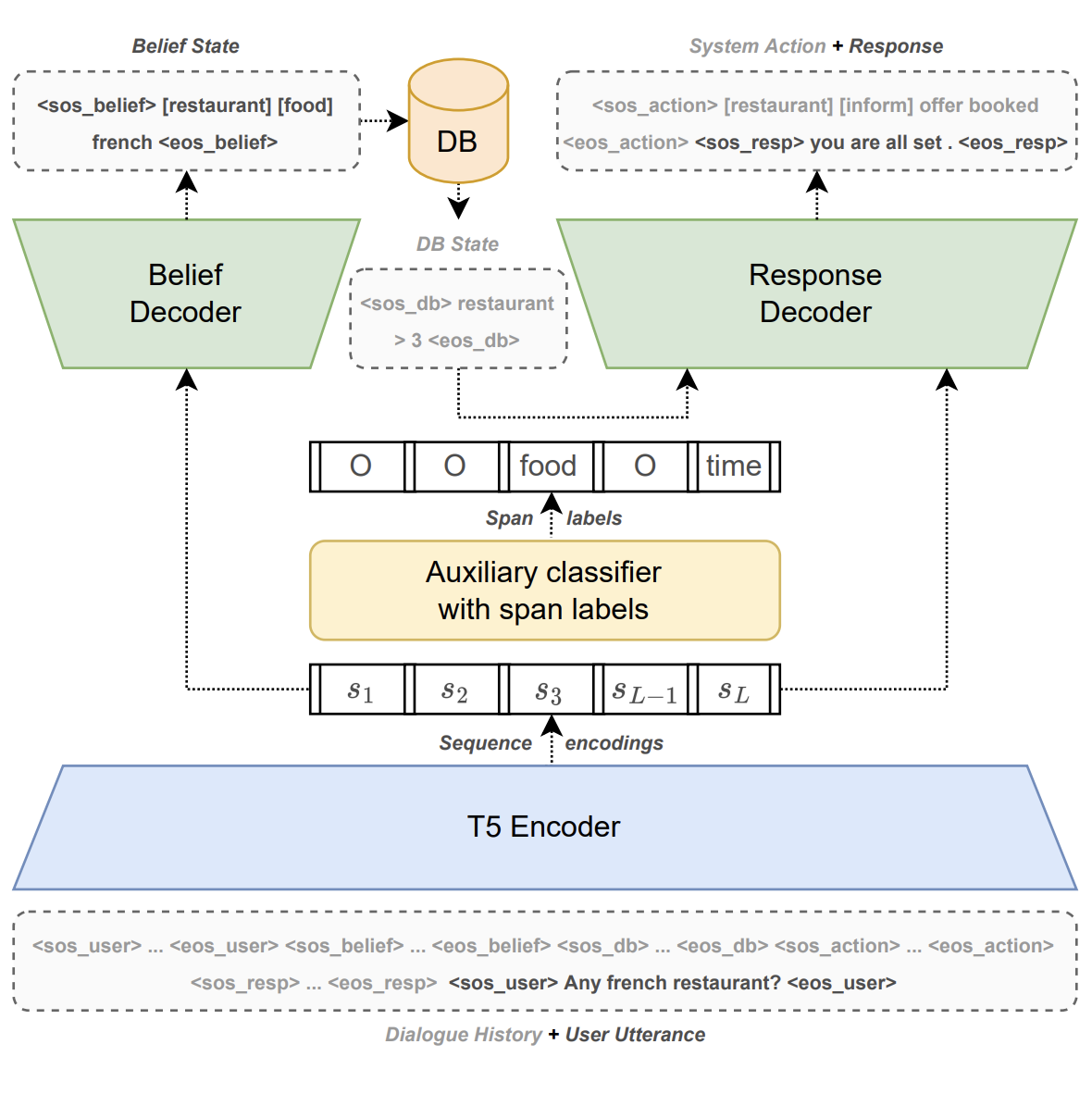
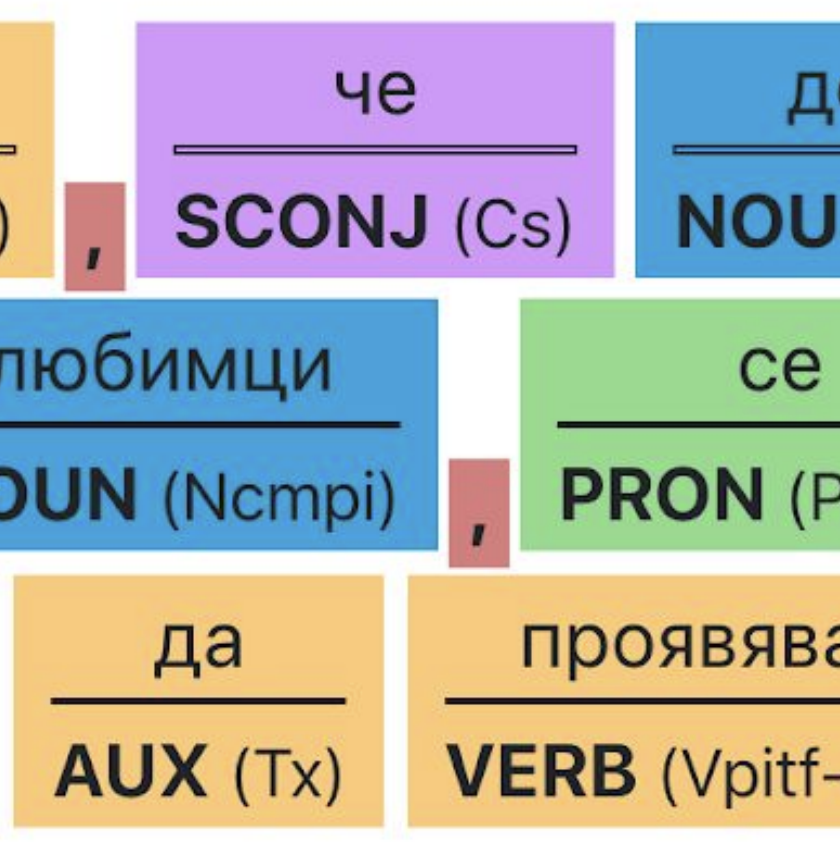
Efficient Task-Oriented Dialogue Systems with Response
Selection as an Auxiliary Task Radostin Cholakov, Todor Kolev ICNLSP, 2022. paper · code We add auxiliary response-selection tasks (distractor vs. ground-truth and synthetic vs. ground-truth) to boost task-oriented dialogue generation. On MultiWOZ 2.1 our models reach state-of-the-art combined scores (107.5/108.3) and outperform a baseline 3× larger, with released code and checkpoints. |
|
AzBuki.ML — Machine learning platform for NLP for the
Slavic languages Radostin Lozanov Cholakov Expo Sciences Luxembourg, 2021. paper · code A full-stack NLP platform featuring a 4M-row word-form dictionary, a POS tagger trained on BulTreeBank and BAS' datasets, a comma prediction BiRNN, and a 45K+ polarity lexicon. Includes experimental embedding and LSTM models for topic modeling, keyword extraction, and both abstractive and extractive summarization. |
Preprints |
|
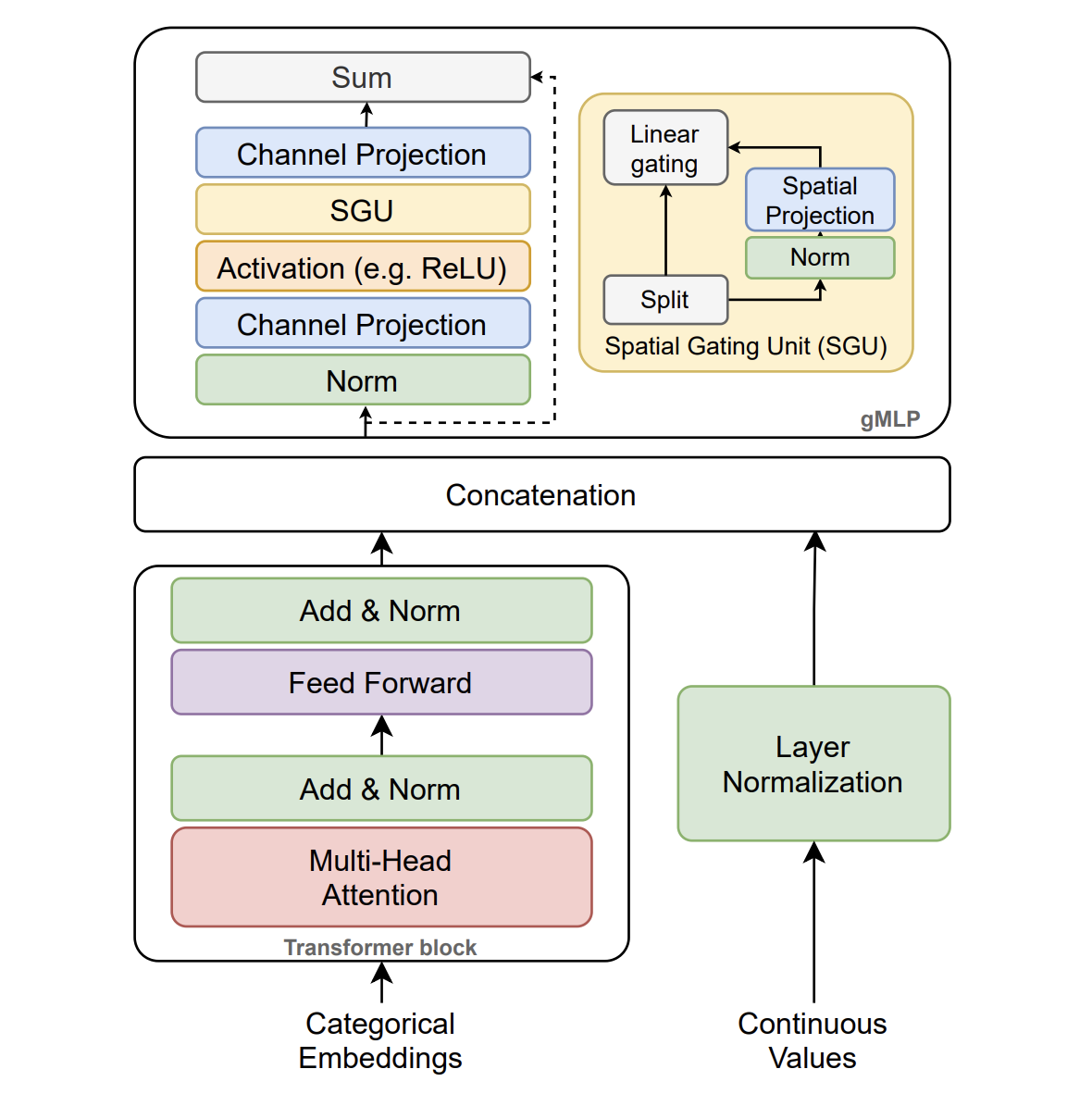
The GatedTabTransformer: An Enhanced Deep Learning
Architecture for Tabular Modeling Radostin Cholakov, Todor Kolev · 2022 · code We extend TabTransformer with gated MLP-inspired linear projections and improved training setups, yielding >1% AUROC gains on three binary classification datasets. We analyze activation choices and key hyperparameters, offering practical guidance for robust tabular modeling. |
|
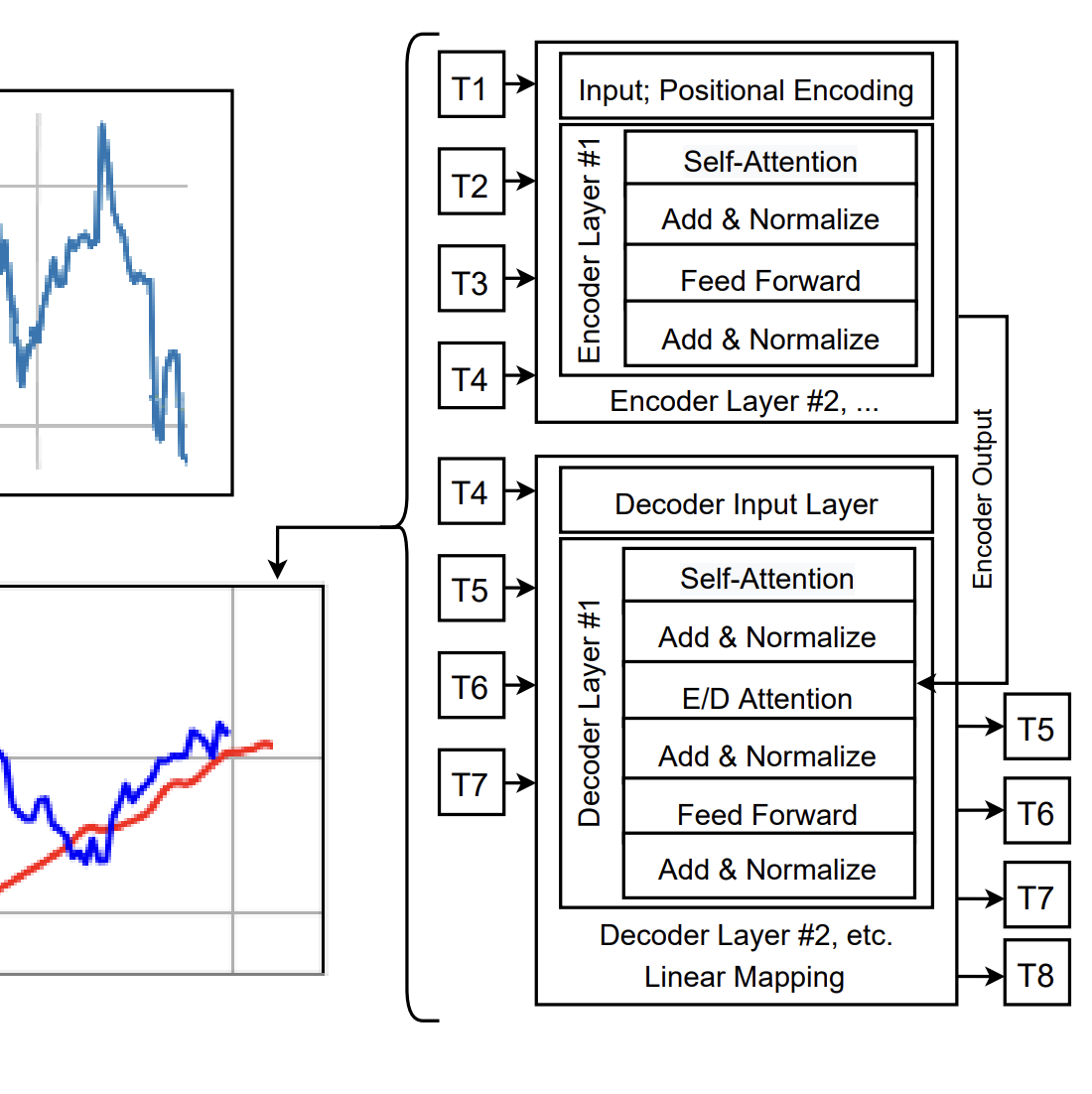
Transformers Predicting the Future: Applying Attention
in Next-frame and Time Series Forecasting Radostin Cholakov, Todor Kolev · 2021 We explore Transformer-style models for time series and next-frame prediction as attention-based alternatives to RNNs across diverse modalities. Our study examines anomaly robustness, context handling, and memory use via preprocessing, dimensionality reduction, and convolutional encodings. |
Projects |
|
LM from Scratch (CS336):
a1 ·
a2 ·
a3 ·
a4 ·
a5, 2025 Radostin Cholakov An implementation of a GPT-style model from scratch, along with tokenization tools, data cleaning pipelines, and post-training scripts. Implemented for the CS336 Spring 2025 course at Stanford by Profs. Percy Liang and Tatsu Hashimoto. |
|
LLaDA r1, 2025 Radostin Cholakov, Zeyneb Kaya, Joe Li, Nicole Ma A remasking optimization head that learns which token positions to remask at each step to improve sample quality and convergence. Winner of the Mercor × Etched × Cognition hackathon; see the announcement for details. Later, wrote a CS224R class project on the topic under the supervision of Minkai Xu at Prof. Stefano Ermon's lab. |

|
ImagiNet dataset, 2024 Delyan Boychev, Radostin Cholakov 200K high-resolution examples across photos, paintings, faces, and miscellaneous for robust synthetic image detection. Two evaluation tracks (real vs. synthetic; generator ID) with SelfCon baselines up to 0.99 AUC. paper |

|
FLUTE, 2024 Han Guo, Radostin Cholakov Contributed improvements for LUT-quantized LLM matmuls, including ≤4-bit non-uniform quantization and RTX 4090 support. Released associated LLaMA and Gemma models on HF. |
|
datasetGPT, 2023 Radostin Cholakov A command-line tool for programmatically generating textual and conversational datasets with LLMs, with pluggable prompting and schemas. Used to build downstream resources such as botbots. |
|
|
GatedTabTransformer in tsai
·
gMLP in tsai, 2022 Radostin Cholakov, Todor Kolev Implemented state-of-the-art tabular and MLP architectures in the `tsai` library (2022), with clean APIs and docs for time series users. Contributions include model definitions, training recipes, and examples. |
Old projects |
|
Technical blog & talks |
|
How AI sees the world: similarities and differences
with human perception? | DEV.BG All in One 2024 Sep 29, 2024 — Talk; video in Bulgarian. |
|
Quantization Approaches for TensorFlow Models | ML
Study Jams TFUG Islamabad Jun 8, 2024 — Talk on weight-only and post-training quantization for TensorFlow models; Also presented at DevFest Sofia: Cloud and Friends. |
|
The power of long contexts: Gemini 1.5 Pro use-cases in
research Mar 24, 2024 — Demonstrates how million-token context enables reasoning over entire manuscripts and long-form media for research workflows. |
|
Fine-tuning the multilingual T5 model from Hugging Face
with Keras Feb 18, 2023 — Minimal tutorial for fine-tuning mT5 for downstream tasks using the Hugging Face ecosystem with TensorFlow/Keras. |
|
Gated Multilayer Perceptron (gMLP): What it is and how
to use it? Sep 10, 2022 — Explains how gMLP works as a non-attention alternative to Transformers and how to use it with TensorFlow/Keras. |
|
Differentiable discrete sampling in TensorFlow Aug 1, 2022 — A practical guide to differentiable sampling for discrete variables used downstream in neural networks. |
|
ML Engine - Machine Learning in the Cloud Oct 4, 2018 — Video on Google Cloud ML Engine on the Fireship channel. |
|
Built from a simplified template (source). |